开云体育甚而逾越了计较自己的亏空-开云官网登录入口 开云app官网入口

跟着东谈主工智能(AI)模子畛域以及应用范围的不休拓展开云体育,性能上限和能耗瓶颈正自由暴露出来。大谈话模子(LLM)、强化学习和卷积神经网罗等 AI 模子的复杂性不休增长,正在将传统电子计较推向极限,动力需求也不休增多。
传统电子计较硬件(如 GPU 和 TPU)的速率和效力由于受到摩尔定律和登纳德缩放定律的遣散,能效瓶颈愈发较着,撑合手 AI 所需的计较智力可能会将现存电子硬件推向极限,与此同期,AI 举座能耗的上涨也导致碳排放增多,对数据中心近邻的电网组成压力。
面对日益增长的计较需求,使用光子而非电子的光子计较为这些挑战提供了一个潜在的管制决策。
本周《天然》杂志上的两篇重磅论文,先容了一种联结“光”和“电”的计较机芯片,展示了诓骗硅基光子学期间的互补冲突。这两项责任诓骗了一种既处理电信号又诓骗光信号的新式芯片,在升迁计较性能的同期也能降稚子耗。
经由本色应用测试,他们建议的电子–光子混统统较系统在要道性能策画上不仅能够与纯电子处理器相比好意思,在某些本色应用中甚而弘扬出特出电子处理器的上风。这秀美着咱们朝着真实竣事光子计较潜能迈出了蹙迫一步。


具体而言,新加坡 Lightelligence 公司 Yichen Shen 团队展示了一种名为 PACE 的光子加快器,这个由逾越 16000 个光子组件组成的大型加快器,接管 64 × 64 的矩阵,能够竣事高速计较(最高达 1 GHz),而况与小畛域电路或单个光子组件比拟,最小延伸减少了 500 倍。这种极低延伸的计较,关于及时处理来说是一个蹙迫的计较速率策画。PACE 也被阐发能够管制被称为“伊辛问题”的复杂计较问题,标明了该系统在本色应用中的可行性。
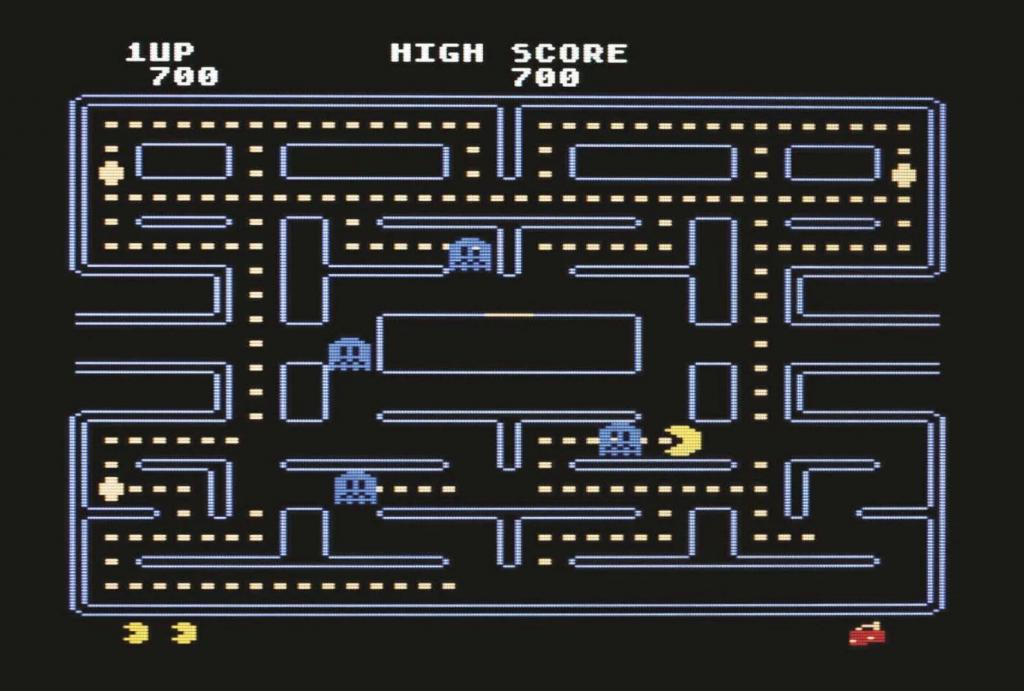
在另一篇稀少的论文中,来自好意思国光子计较机公司 Lightmatter 的 Nicholas Harris 团队描写了一种能够高效高精度履行 AI 模子的光子处理器。该处理器由四个 128 × 128 的矩阵组成,不错履行天然谈话处理模子 BERT 和用于图像处理的神经网罗 ResNet,其精度与传统电子处理器不相高下。商榷东谈主员还演示了该光子处理器的多种应用,包括生成莎士比亚格调的文本、准确分类电影挑剔,以及玩经典的 Atari 电脑游戏《吃豆东谈主》等。
两个团队均暗示,他们的系统是可膨胀的,还有进一步优化的空间。“光子计较依然发展了几十年,但这些演示可能意味着咱们终于不错诓骗光的力量来构建更执意、更节能的计较系统。”在 Nature 同期发表的一篇挑剔著述中,达特茅斯学院工程学助理讲授 Anthony Rizzo 暗示。
光子计较,不再受制于晶体管遣散的计较期间
在计较机和 AI 期间高速发展的今天,内存拜谒和数据传输占据了绝大部分 AI 责任负载的能耗和履行时刻,甚而逾越了计较自己的亏空。即使计较单元简直不亏空能量,举座效力仍然受到数据传输的遣散。
计较期间也正处在一个前所未有的移动点。AI 责任负载对计较智力的需求依然特出了传统膨胀定律(如摩尔定律、登纳德缩放定律和内存膨胀定律)所能提供的智力。这三项定律,尤其是在每单元硅面积的基础上,依然基本停滞。
近几十年来,科学家们一直在探索寻找新的计较期间,以管制基于晶体管架构的固有遣散。
举例,量子计较能够在某些问题上竣事指数级加快,但现在在纠错、可膨胀性和保合手有关性方面濒临挑战。此外,为量子计较机创建可阐发比经典计较机算法更高效的算法也存在贫乏;DNA 计较诓骗分子级并行性,但濒临显耀的本色阻隔,包括操作速率慢以及与传统计较系统接口的贫乏;类脑计较和模拟计较方法提供了受生物神经网罗启发的私有信息处理花样,但频频短少天真性、通用适用性和与现存算法的兼容性;基于碳纳米管的处理器旨在取代硅晶体管,但仍然受到鸠合纳米管计较元件的电气廓清充放电所需的能量和时刻本钱的遣散。
光子学行动一种替代传统电子期间的决策,因其具有高带宽、低延伸、神气并行化等固有上风,以及通过光基计较竣事更高能效的后劲而备受温存。光子计较是一种诓骗光信号进行计较的期间。光子计较的上风在于光的速率极快,光信号的带宽很高,而且光子计较的能耗更低。换句话说,光子计较就像是“信息高速公路”,不错让数据传输和处理变得更加高效。
而且,光子计较具有更高的并行性和更低的功耗,表面上不错显耀升迁计较速率和能效。此外,矩阵乘法和累加(MAC)运算是 AI 的中枢机较操作,使用光子电路不错更快、更高效地完成这些操作。近些年来,科学家们依然设置了包括诓骗时刻 - 波长交错调制和光电乘法的光子加快器,展示了朝真的用光子处理器在 AI 任务中应用迈出的蹙迫一步。
光子计较行动一种有后劲的商榷领域依然存在了数十年,但其在本色应用中的推论一直受到制约,原因在于短少能够竣事芯片级、可畛域化坐蓐的光学处理单元。尽管一些着手进的展示阐发了集成光子学在加快计较方面的后劲,但这些光子芯片的性能评估大多是在单独测试中进行,而试验系统中的数据大多依赖于电子领域。因此,光子计较必须与电子期间细腻集成,共同瞎想才能阐扬出最好性能。
事实上,这两项期间并非相互竞争,而是各有长处、互为补充。具体来说,光子期间在履行线性运算时(即输入与输出数据之间存在线性、成比例关联的情况)弘扬得更为高效;而电子期间则在处理非线性运算时(即输入与输出数据之间通过复杂数学函数关联,而不再保合手浮浅比例关联)具有更大上风。
PACE:首个基于商用硅光子期间竣事的大畛域光子加快器
光子计较的后劲尚未十足竣事,主要受限于大畛域集成和复杂电路瞎想的挑战,包括光学信号与电子信号的协同集成和转变、在大畛域复杂电路中类比计较的精度问题,以及妥当光子硬件的算法和模子设置。
Yichen Shen 团队先容了一种基于大畛域集成光子期间的光子加快器系统 PACE,该系统能够竣事超低延伸的矩阵乘法与累加(MAC)运算,并在管制计较复杂度高的问题(如 Ising 问题)方面弘扬出显耀的性能上风。
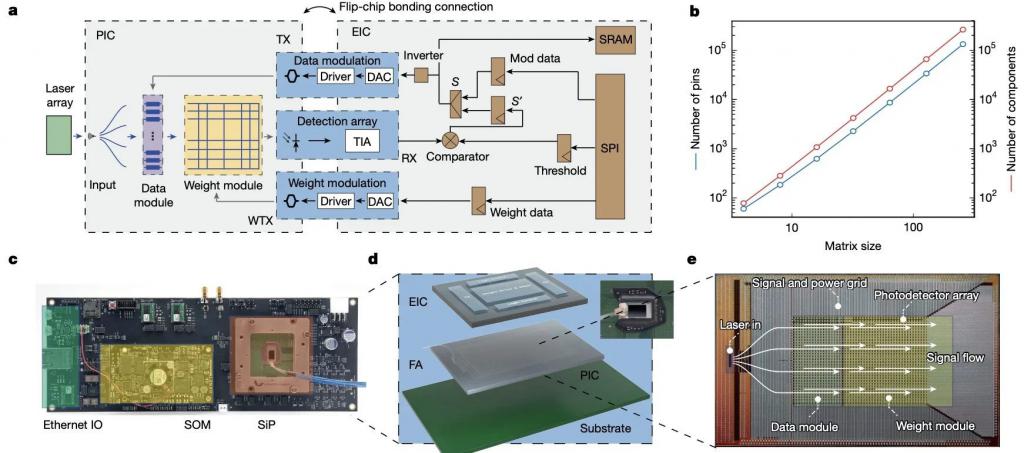
具体而言,商榷团队基于商用 65 纳米硅光子期间,集成了逾越 16000 个光子组件,建议了一种 64 × 64 的 PACE。而且 PACE 接管光电协同集成瞎想,将光子集成电路(PIC)和电子集成电路(EIC)封装在一个系统级封装(SiP)中。电子芯片基于 28 纳米 CMOS 期间,矜重数据输入、输出和逻辑适度。
他们将光子芯片和电子芯片通过 2.5D 封装期间细腻集成在一个封装内,竣事高密度信号鸠合,从而能够支合手大畛域矩阵运算。系统通过光调制器和探伤器竣事高速光电信号转变,并通过镶嵌式静态速即存取存储器(SRAM)管制数据存储。
性能方面,他们将 PACE 的弘扬与一款着手进的 NVIDIA A10 GPU 在管制波及 64 × 64 矩阵乘法的伊辛模子时的弘扬进行了对比,遣散炫耀在最小延伸这一要道策画上,计较时刻从 2300 纳秒裁减到仅 5 纳秒,近乎竣事了 500 倍的纠正。此外,PACE 的延伸膨胀整个约比 TPU 低 1000 倍,这意味着跟着矩阵畛域的增大,其延伸上风会更加显耀。
此外,系统通过引入可控噪声(来自激光器、模拟驱动器和数字电路)竣事高效的比特翻转,从而提高算法的搜索效力。并通过严格的器件规格适度和校准,系统竣事了平均 7.61 位的灵验精度(ENOB),并能够在 ± 5 ° C 的温度波动下保合手雄厚。能效方面,PACE 的能效达到 4.21 TOPS/W(不包括激光器)和 2.38 TOPS/W(包括激光器),显耀优于传统电子计较平台。
商榷东谈主员暗示,PACE 是首个基于商用硅光子期间竣事的大畛域光子加快器,该系统在延伸和计较速率方面的显耀上风,为光子计较在 AI、优化问题和及时处理等领域的应用奠定了基础。与传统 GPU 比拟,PACE 在延伸和计较时刻上竣事了两个数目级的升迁,为光子计较的生意化和大畛域应用提供了蹙迫参考。
商榷东谈主员也指出,通过进一步优化器件瞎想和信号处理,改日光子加快器的延伸不错贬低到 3 纳秒以下。光子计较也有望成为管制复杂计较问题的新一代计较平台,绝顶是在需要高费解量和超低延伸的场景中。
新式光子 AI 处理器:已开玩《吃豆东谈主》
从更宏不雅的角度来看,计较期间的改日需要在内存、互连和计较 3 个要道领域获得冲突。设置一种可膨胀的、访佛 DRAM 的内存管制决策仍然是一个要紧且未管制的挑战,现在尚无明确的实用管制决策。
Nicholas Harris 团队先容了一种窜改性的光子处理器,通过 Lightmatter 冲突性光子互连期间 Passage 显耀贬低数据传输能耗并提供超高带宽,为这一要道瓶颈提供了管制决策。
这种新式的光子 AI 处理器能够开动常见的 AI 模子,比如 ResNet(用于图像分类)、BERT(用于文分内析)以及 DeepMind 的 Atari 强化学习算法(用于游戏决策),通过光子芯片竣事了接近传统电子计较的精度,同期具有更高的能效。
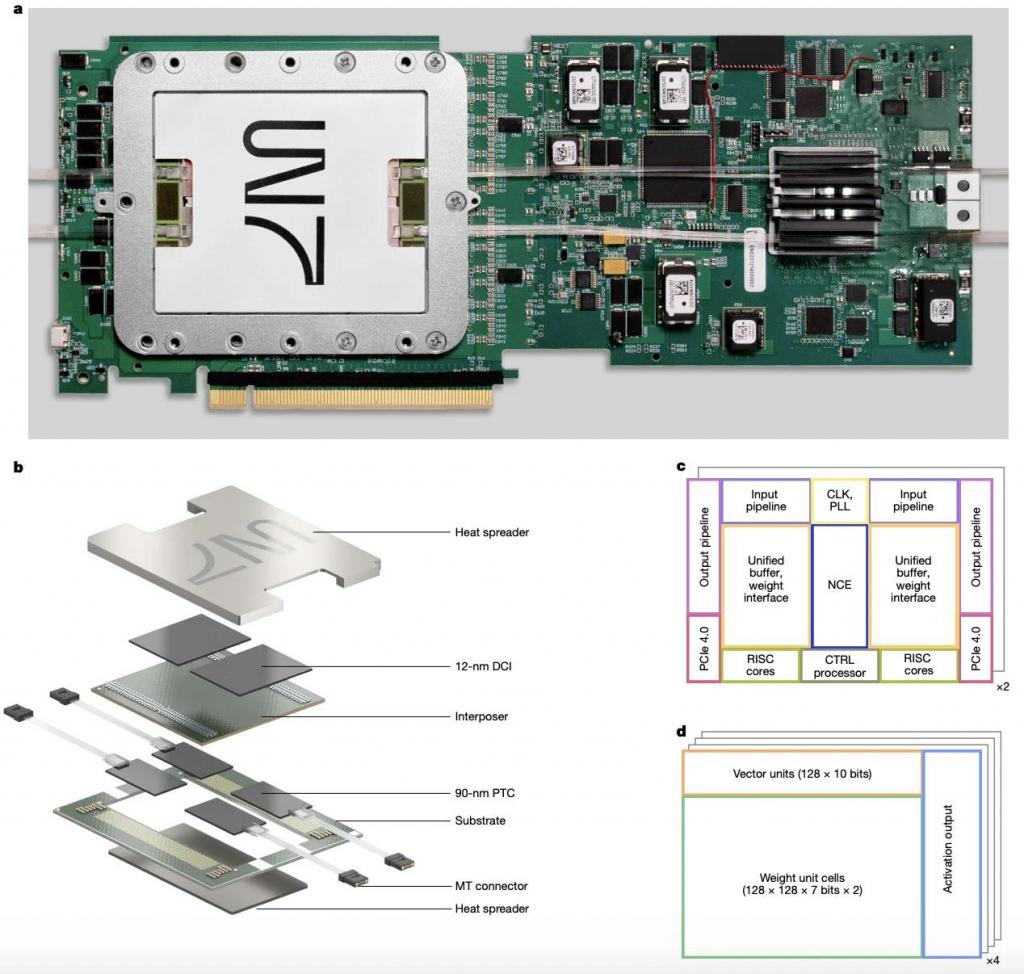
具体而言,该光子 AI 处理器集成了四个 128 × 128 的光子张量中枢(PTC,矜重光信号的计较),每个 PTC 包含 128 个 10 位光子向量单元和 128 × 128 个 7 位权重单元。PTC 通过高速光电信号与数字适度芯片(DCI,管制光子芯片的开动,并将光信号转变为数字信号)接续,竣事了高效的数据传输和处理。
性能弘扬上,该处理器在 78 瓦的电功耗和 1.6 瓦的光功耗下,每秒可履行 65.5 万亿次 16 位自适合块浮点(ABFP)运算。这是现在光子处理器中最高的集成水平。
精度方面,该处理器在多个 AI 任务中弘扬出与 32 位浮点计较绝顶的精度,举例 ResNet 18 在 CIFAR-10 数据集上的分类准确率达到 97.8%,与传统电子硬件绝顶。
任务智力上,该光子处理器不错履行分类任务(如识别图像)、总结任务(如展望数值)和强化学习任务(如玩复杂的游戏)。其中在分类任务 ResNet18 等模子上弘扬出与数字平台绝顶的分类准确率;在总结任务(如 SQuAD)中,由于光子计较的噪声明锐性,该处理器的性能略有下落;在强化学习算法上,该处理器能够开动 Atari 游戏,尽管性能略低于 FP32 处理器,但展示了其在复杂决策任务中的后劲。
商榷东谈主员以为,这项商榷的兴趣兴趣在于展示了光子计较在 AI 领域的浩瀚后劲。光子处理器的高能效和高性能使其成为改日 AI 硬件的有劲竞争者,尤其是在需要处理大畛域数据和复杂模子的场景中。这种处理器的到手开动,也为后晶体管时间的计较期间提供了一种新的可能性,也为改日 AI 硬件的发展指明了场所。
计较期间的一个历史时刻
光子计较的发展已酝酿数十载,如今这些全新的冲突性遣散或者意味着咱们行将真实诓骗“光”的力量,打造出更执意且更节能的计较系统。
光子芯片在能效和性能上的上风,使其成为改日 AI 硬件的有劲竞争者,尤其是在大畛域数据处理和复杂模子测验中。而光子芯片的到手开动阐发了其在本色 AI 任务中的可行性,为改日光子 AI 硬件的生意化和应用奠定了基础。
商榷东谈主员也指出,光子芯片代表了一个令东谈主粗豪且必要的新前沿,最新的商榷遣散意味着计较期间的下一章无用受制于晶体管的遣散,这代表着计较期间的一个历史时刻。不外,这并不料味着电子计较将隐匿,相背,咱们正在插足一个多种计较范式共存的时间。
尤其值得可贵的是,这两项遣散演示中所用的光子芯片和电子芯片均是在要领的互补金属氧化物半导体(CMOS)厂房中制造的,也恰是现在用于坐蓐微电子芯片的厂房。因此,现存制造基础才略不错被赶紧诓骗以竣事大畛域坐蓐。
另外,两套系统均已通过要领“主板”接口(期间上称为外设组件互联高速接口)竣事了无缺集成,从而使其能够与现存的各类接口及合同兼容。这是计较历史上初次展示一种非晶体管期间能够以与现存电子系统绝顶的精度和效力开动复杂的真实责任负载。这种从表面可能性到本色实施的移动秀美着计较期间的新篇章,考据了光子学行动一种能够显耀影响 AI 处理改日发展的可行管制决策。
不外,天然光子处理器依然获得了显耀进展,但要思将光子计较澈底行动电子芯片的生意替代决策,仍存在不少期间阻隔。举例,若何进一步提高精度、贬低功耗,以及若何优化材料和制造工艺等。尽管如斯,咱们仍有充分情理期待光子芯片在不久的将来能够走入试验系统。
参考良友:开云体育



